
The term “filter bubble,” coined by Eli Pariser, captures how social platforms can trap us in narrow content silos. YouTube is no exception: its algorithm often serves up videos from the same handful of channels we already watch—boosting our dwell-time and, ultimately, the platform’s ad revenue.
These bubbles don’t just limit what we watch—they can subtly shape our worldview. Traditional “collaborative-filtering” algorithms lean heavily on what’s already popular, reinforcing mainstream tastes while burying emerging creators and fresh perspectives that haven’t yet racked up views.
Thanks to large language models (LLMs), building a personalized recommender is now within reach of any developer. In this post, I introduce a lightweight YouTube recommender I recently built: one self-contained Python script, fully open-sourced on GitHub, and ready for you to tailor to your own viewing goals and discovery preferences.
The Recommendation Pipeline
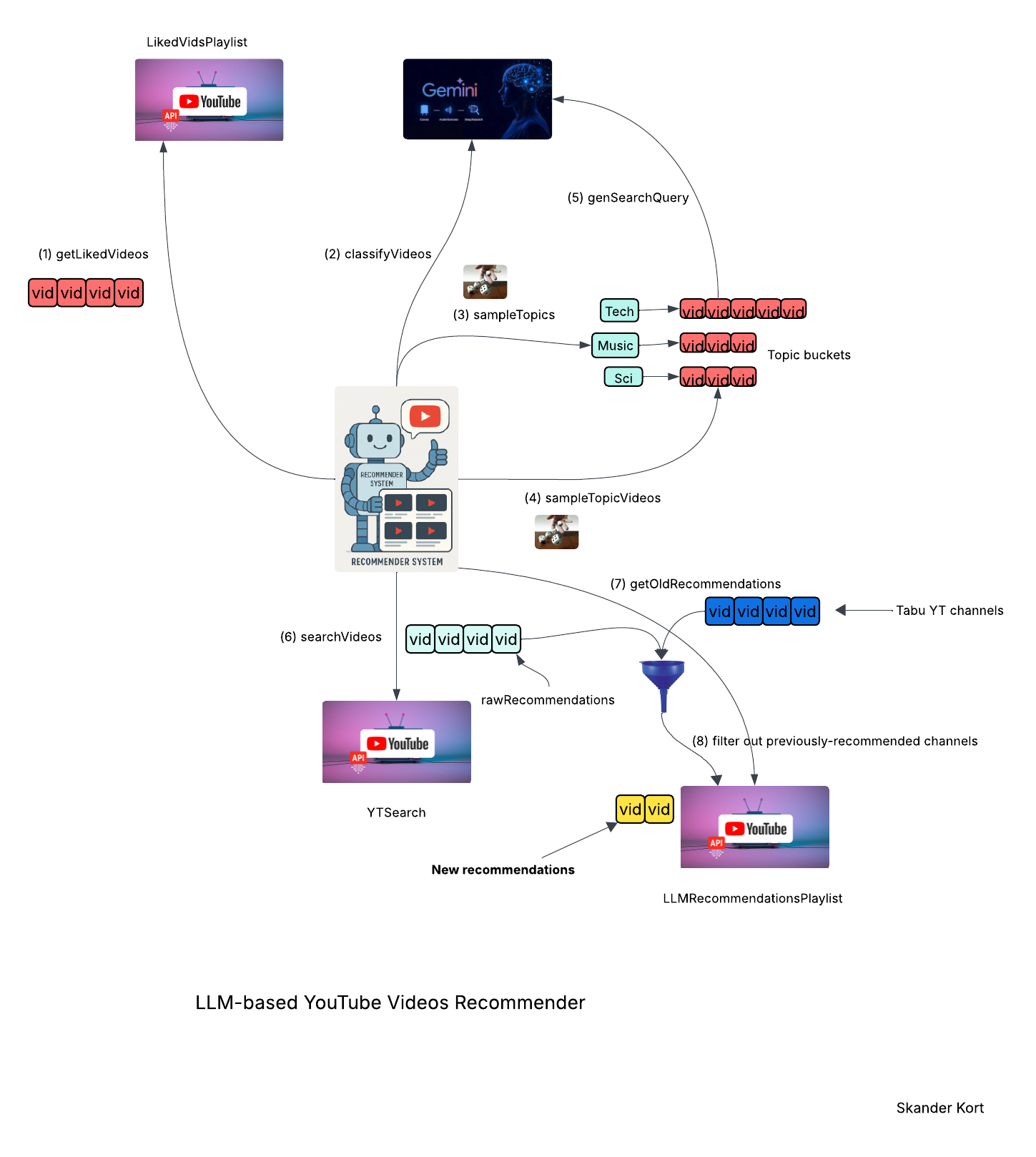
The diagram above shows the end-to-end pipeline. All orchestration is hand-coded in vanilla Python—no autonomous LLM agents—so I retain complete control over each step. I invoke the LLM only where it truly excels:
- Semantic classification: grouping videos by topic based on natural-language cues.
- Multilingual coverage: understanding languages and translating on the fly.
- Dynamic phrasing: generating concise, yet diverse search queries.
Under the hood, the script taps the YouTube Data API and Google’s gemini-2.0-flash model (easily swappable for any LLM you prefer). The recommendation pipeline then unfolds through eight stages:
- Fetch recent likes – The script queries the YouTube Data API for the user’s 1,000 most-recently liked videos.
- Topic-tag with an LLM – Each title is sent to the LLM, which: maps it to a curated list of YouTube categories (adding new ones if needed); works seamlessly across input languages; but labels topics in English for consistency; returns “topic buckets” that let us sample recommendations independently from each category.
- Pick the themes – From those buckets, the program uniformly selects five distinct topics (no repeats) to guarantee a varied recommendation set.
- Choose seed videos – From every chosen topic bucket, the script uniformly picks three unique videos. These 15 seeds serve as the launch-pad for generating fresh, topic-balanced recommendations.
- Generate YouTube search queries – For each topic, the LLM takes the topic name, the three seed videos (title + description), and a pool of target languages; it identifies a representative sub-topic, formulates a precise YouTube search query for that niche, optionally rephrases it for diversity, and then translates the query into a randomly chosen target language.
- Search YouTube – Run the five LLM-generated queries through the YouTube Data API and keep only high-quality, long-form videos.
- Retrieve previous recommendations – All prior picks live in a user-created LLM Recommendations playlist; before proceeding, the script pulls the 200 most recent entries from that playlist for filtering and housekeeping.
- Select video recommendations – After excluding videos from channels you’ve watched lately, the script adds two fresh picks per topic to the LLM Recommendations playlist.
Tailor it to Your Needs
I’ve been running the script as a daily cron job on a VPS for just over a week, and it’s already surfacing gems I’d never have seen—like an ACM SIGPLAN talk on the Wolfram Language with only 924 views. Once I started watching items from my LLM Recommendations playlist, YouTube’s own algorithm began breaking out of its usual bubble and serving up a far broader mix of content. Here are a few levers you can tweak to make the tool your own:
- Tweak the top-of-file settings to control how many liked videos you pull, how many topics you sample, which languages your search queries target, and which default categories seed the process.
- Instead of treating all buckets equally, you can weight the draw by bucket size—proportionally to favor popular categories, or inverse-proportionally to give under-represented topics a better shot at being selected.
- Prefer precision? Swap out random sampling for a whitelist of must-have topics so the recommender zeroes in on them—or keep the randomness while adding a blacklist to ensure unwanted categories never make the cut.
- Switch from uniform sampling to an exponential-decay curve, boosting the odds that older, long-forgotten favorites resurface in your recommendation seeds.
- Refine the LLM prompt that creates each search query—for opinion-driven topics, you can explicitly instruct the model to hunt for videos that present viewpoints opposite to those expressed in your seed set.
Smooth Deployment & Common Pitfalls
- Full setup is spelled out in the GitHub README: create a new Google Cloud project, enable both YouTube Data API v3 and the Gemini generative-AI API, generate an API key, and add OAuth 2.0 credentials for the YouTube endpoints.
- While the project is in “testing” mode, add your YouTube account’s email to the OAuth consent screen’s Test Users list.
- Specify a redirect URI—for example, http://localhost:9090/—in your OAuth client settings. After initial consent, Google forwards the user to this exact address, so be sure the URI (including the trailing slash) matches identically in both the Cloud Console and the script.
- Create a new playlist—say, LLM Recommendations—via YouTube’s web interface (private is fine) and set its order to manual. The script inserts each new video at position 0, so manual sorting ensures the freshest picks always appear at the top.
- Copy .env.example to .env, then populate it with your API key, OAuth 2.0 client secrets, and the ID of your LLM Recommendations playlist.
- Switch the project out of “testing” and into “production” (no Google review needed for personal use) so Google issues a non-expiring refresh token—letting the script renew OAuth credentials automatically.
- YouTube Data API v3 gives you a 10,000-point budget every 24 hours. Reads are cheap—fetching 50 liked videos costs 1 point, so pulling your latest 1,000 likes burns only 20 points. Writes and searches are pricier: adding or removing a single video from the LLM Recommendations playlist costs 50 points, and each search query consumes 100 points. Keep these numbers in mind when tuning the script, or you’ll quickly hit a quotaExceeded error.
I hope this tool proves as useful for you as it has for me—and that you’ll enjoy tailoring it to suit your own tastes. Building your own recommender is a bit like home-cooking: you choose the ingredients, the portions, and the spice, instead of relying on someone else’s take-out menu.