
I- In the Beginning
Promptheon is an LLM-powered system for exploring and structuring knowledge about ancient deities from Wikipedia. The project begins by crawling the List of Deities category page, using a Gemini-based language model to classify portal links by cultural origin or divine role. Each portal is then crawled to extract linked pages, which are filtered by another LLM call to retain only deity-related entries. For each identified deity, the corresponding Wikipedia page is fetched, and inherited role/culture metadata is attached. The resulting collection is stored in a vector database, enabling efficient semantic search. The second phase of the project transforms Promptheon into an agentic application. A ReAct-based agent receives user queries about ancient deities, uses the vector store to retrieve relevant pages, and calls an LLM to identify potential symbolic relationships between them. It then computes semantic similarities between the deities and constructs a deity graph—with edges labeled by relationship types and weighted by semantic closeness. Finally, this graph is rendered using NetworkX, allowing users to explore both symbolic and semantic connections between deities in a visual way.
This work was conducted as a capstone project (Kaggle notebook here) for the five days GenAI course offered by Google and Kaggle in April 2025.
II - Architecture
The architecture of Promptheon is outlined in the diagram below.
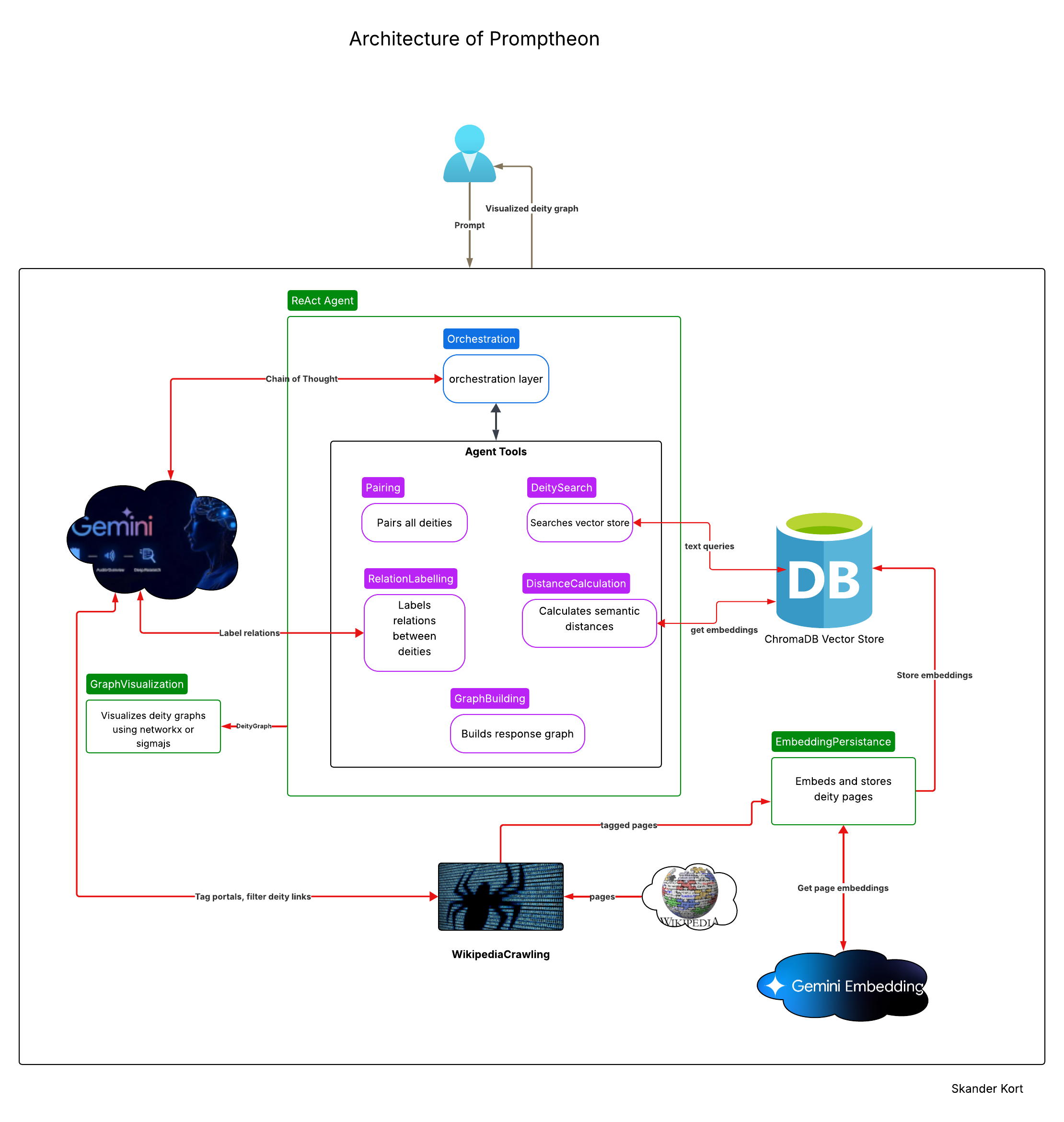
Promptheon is an interactive application designed to explore user-submitted prompts about ancient gods and goddesses. When a query is entered, the system retrieves relevant information and generates a visual graph that connects the resulting deities. Each connection (or edge) between deities is labeled to indicate the type of relationship, while the thickness of the edge reflects their semantic proximity—thicker edges imply stronger conceptual or contextual similarity.
The system is composed of four core components: a large language model (LLM)-powered Wikipedia crawler, an embedding and persistence layer, a ReAct agent responsible for processing user prompts and generating the corresponding deity graph, and finally, a visualization module that renders the resulting graph. Each of these components is briefly outlined below.
- WikipediaCrawling: This component gathers deity-related content by crawling Wikipedia, starting from a set of seed links defined by a specific category page. Each portal link is automatically tagged with cultural and deity role metadata. The crawler then visits each portal page and selectively extracts links to individual deity entries, ensuring focused and relevant data collection.
- EmbeddingPersistence: This component receives the tagged deity pages collected by the Wikipedia Crawling module. Each page is segmented into multiple text chunks, and for each chunk, an embedding vector is generated using a Gemini embedding model. These vectors, along with the corresponding text and associated metadata, are then stored in a ChromaDB vector store for efficient retrieval.
- The ReAct agent: This component serves as the brain of the Promptheon application. It orchestrates multiple tools to fulfill end-user queries. These tools enable the agent to search the ChromaDB vector store, identify and label relationships between deities, compute semantic distances between deity documents, and construct the final deity graph that represents the query response.
- GraphVisulization: This component takes the deity graph produced by the ReAct agent and renders it using the NetworkX library. Nodes are colored based on their degree of connectivity, providing visual cues about their centrality within the graph. Edge thickness is determined by semantic distance—thicker edges indicate stronger semantic similarity between the connected deities.
III- The ReAct Agent
This section outlines the implementation of Promptheon’s ReAct agent. We begin by describing how the agent is constructed and initialized. We then delve into the implementation of the RelationLabelling tool, which enables the agent to identify and annotate relationships between deities. Finally, we demonstrate the agent in action as it processes a search query and constructs the corresponding deity graph.
III.1- Building and Initializing the Agent
For this project, I used LangChain’s ReAct agent architecture, powered by the gemini-2.0-flash language model. The agent’s prompt was based on the hwchase17/react template, which served as a foundation for building a customized prompt tailored to Promptheon’s needs. However, to ensure consistent and structured outputs—specifically, the generation of deity graphs rather than simple lists of names—the base prompt was augmented with explicit response formatting instructions. The snippet below illustrates how the ReAct agent was constructed and initialized.
# Agent's underlying LLM.
agent_llm = GoogleGenerativeAI(model=LLM)
# Tools to be provided to the agent.
agent_tools = [
search_deities,
create_deity_pairs,
get_deity_relations,
calculate_relation_distances,
format_output
]
# ReAct agent prompt.
base_prompt = hub.pull('hwchase17/react')
# Create a Pydantic output parser to make the agent return structured output instead of freeform text.
parser = PydanticOutputParser(pydantic_object=DeityGraph)
agent_format_instructions = parser.get_format_instructions() + """
IMPORTANT: When you call *any* tool, your **Action Input** must be valid JSON.
• Strings must use double‑quotes (")
• Objects use { } and arrays use [ ]
• No Python literals (no single‑quotes, no bare brackets)
Example of a correct call:
Action: create_deity_pairs
Action Input: {"deities": ["Poseidon", "Zeus", "Helios"]}
Now invoke the tool exactly in that format—nothing else.
Your final answer MUST always be a DeityGraph.
"""
# Inject the extra formatting instructions in the final prompt
agent_prompt: PromptTemplate = base_prompt.partial(
format_instructions=agent_format_instructions
)
# Create agent and its executor.
agent = create_react_agent(
llm=agent_llm,
tools=agent_tools,
prompt=agent_prompt
)
agent_executor = AgentExecutor(
agent=agent,
tools=agent_tools,
handle_parsing_errors=True,
verbose=True)
At its core, creating a ReAct agent involves specifying the underlying LLM, defining the set of tools the agent can access, and providing a prompt template that includes required placeholders—such as {tools}—to guide the agent’s behavior. One important consideration when migrating a local Jupyter notebook to the Kaggle platform is environment variable management. Specifically, the GoogleGenerativeAI client expects the GOOGLE_API_KEY to be set as an environment variable. If your local setup relies on .env files to manage secrets, you’ll need to explicitly set this key in your Kaggle notebook using the platform’s "User Secrets" feature. Failing to do so may cause the agent to hang silently when invoked, as it cannot authenticate with the API.
The agent_executor serves as the orchestration layer depicted in the architecture diagram and is a component of the LangChain framework.
III-2 On Reasoning and Tools
ReAct stands for Reasoning and Acting. A ReAct agent typically operates in cycles of Thought → Action → Observation, which loosely mirror the scientific method: form a hypothesis, experiment, observe, and iterate until a satisfactory result is reached. Before working on this project, I tended to associate “reasoning” in generative AI with formal logic or symbolic systems. However, that’s not quite how things work. In practice, agents simulate reasoning through iterative text generation—and surprisingly, they’re quite effective at it, as we’ll see in the next section.
The architecture diagram above includes an interaction arrow between the agent’s orchestration layer and a Gemini LLM. To draw an analogy with traditional computer architecture, a CPU consists of a control unit and an arithmetic and logic unit (ALU). At first glance, the orchestration layer of a ReAct agent might appear to play the role of the control unit. But in reality, it’s the LLM that drives the process.
Through text generation, the LLM determines which tool to invoke and what arguments to pass. It constructs this as a string, which is handed off to the orchestration layer. The orchestration layer parses the string, validates the tool call, and executes it—much like an ALU responding to instructions from the control unit. In this analogy, the LLM is the control unit, while the orchestration layer acts more like a specialized ALU with added coordination responsibilities.
This architecture has a significant implication: crafting effective agent behavior requires guiding the LLM thoughtfully. One useful technique is to fine-tune the docstrings of the available tools. These docstrings shape how the LLM interprets and selects tool calls.
Let's take a closer look at the implementation of one such tool: RelationLabelling.
# Identify the relation between a pair of deities and label it.
# get_deity_relation_v1
# type: few-shot
# format-output: Yes
# schema: DeityRelationsResponse
get_deity_relation_v1 = """You are an expert in ancient religions and deities.
You are given a list of pairs of deity names DEITY_PAIR_LIST.
Your task is to identify the relation between each pair of these deities, if any. Identified relations should be obvious and
intuitive. All relations must be symmetrical: not oriented from one deity to the other. Acceptable relations include family
relations, relations based on deity roles and syncretism of deities.
* EXAMPLE 1:
INPUT: [("Zeus", "Hera"), ("Cronos", "Zeus"), ("Zeus", "Jupiter"), ("Zeus", "Tanit"), ("Zeus", "Athena")]
OUTPUT:[("Zeus", "Hera", "husband-wife"), ("Zeus", "Cronos", "father-son"),
("Zeus", "Jupiter", "syncretism"), ("Zeus", "Athena", "father-daughter"), ("Zeus", "Tanit", "unknown")]
* EXAMPLE 2:
INPUT: [("Shahar", "Aurora"), ("Aphrodite", "Ishtar"), ("El", "Baal"), ("Surya", "Ishtar"), ("Inana", "Nammu")]
OUTPUT: [("Shahar", "Aurora", "dawn-deities"), ("Aphrodite", "Ishtar", "fertility-deities"),
("El", "Baal", "father-son"), ("Inana", "Nammu", "modther-daughter")]
You must answer in JSON format.
RESPONSE JSON SCHEMA:
DeityRelation = {"source": string, "target": string, "relation_label": string}
RESPONSE: {"relations": List[DeityRelation]}
DEITY_PAIR_LIST: {{deity_pair_list}}
"""
DEITY_PAIR_CHUNK_SIZE = 500
@tool
def get_deity_relations(
deity_pairs
) -> List[Tuple[str, str, str]]:
"""
Returns the deities that are related to each other and the type of this relation.
The input can be a stringified list or an actual list of deity pairs. This function
normalizes the input, then processes it in chunks to avoid exceeding the LLM's context window.
A delay is added between LLM calls.
Returns a list of (source, target, relation_label) tuples.
"""
# Normalize input
deity_pairs_list = parse_list_arg(deity_pairs)
all_relations = []
# Configure LLM call once
llm_config = GenerateContentConfig(
temperature=0,
responseSchema=IdentifyDeityRelationsResponse,
responseMimeType='application/json'
)
# Process in chunks
for i in range(0, len(deity_pairs_list), DEITY_PAIR_CHUNK_SIZE):
chunk = deity_pairs_list[i:i + DEITY_PAIR_CHUNK_SIZE]
prompt = get_deity_relation_v1.replace('{{deity_pair_list}}', str(chunk))
response = client.models.generate_content(
model=LLM,
config=llm_config,
contents=prompt
)
all_relations.extend(response.parsed)
return all_relations
The RelationLabelling tool is implemented through the get_deity_relations function. This function takes as input a list of deity name pairs and returns a list of triplets, where each triplet consists of two deities and the inferred relationship between them.
The get_deity_relations function is exposed as an agent tool using the @tool decorator provided by LangChain. This decorator requires a descriptive docstring, which guides the LLM in determining when and how to invoke the tool. In practice, the quality and clarity of the docstring significantly influence the agent’s behavior.
During development, I encountered an issue where the agent_executor did not respect the expected input signature of the tool function—instead of passing a list, it provided a serialized string. To address this, I manually deserialized the input using the parse_list_arg utility, as seen in the line:
deity_pairs_list = parse_list_arg(deity_pairs)Internally, get_deity_relations calls the LLM to infer the relationships between the given deity pairs. This call relies on a few-shot prompt template defined in the variable get_deity_relation_v1, which provides two example pairs to guide the model toward higher-quality outputs. The LLM is instructed to return a structured response conforming to a predefined schema, detailed below.
class DeityRelation(pydantic.BaseModel):
source: str = Field(..., description="Name of source deity")
target: str = Field(..., description="Name of target deity")
relation_label: str = Field(..., description="Label of relation between source and target deities")
class IdentifyDeityRelationsResponse(pydantic.BaseModel):
relations: List[DeityRelation]
To avoid exceeding the LLM's context window, calls to the model are processed in chunks. I selected a chunk size of 500, after observing that chunk size has a noticeable impact on the quality of the relation labels. Extremely small chunks (and, interestingly, very large ones) tend to degrade the relevance and consistency of the inferred relationships.
Another important design decision was to ensure that the tool returns all input deity pairs, even when no clear relationship exists between them. In such cases, the LLM is instructed to label the relationship as "unknown". This approach was necessary to preserve all nodes in the graph across tool invocations. Since the ReAct agent does not maintain internal state, omitting pairs with no relation would result in missing nodes downstream. These "unknown" relations propagate through subsequent tools and are ultimately filtered out by the GraphBuilding tool—the final step in the agent’s reasoning chain.
III.3 Promptheon in Action
Now, let’s prompt the agent and observe how it processes our query. We submit the following request:
"Give me at least 5 deities from Greece, 5 Mesopotamian deities, and 7 deities from Canaan."
What follows are the reasoning and action steps the agent takes to fullfill this prompt, as it constructs a structured response.
The agent receives the prompt and correctly interprets the user's request.

The agent initiates three distinct search queries—one for each pantheon—by invoking the search_deities tool. Crucially, it is explicitly instructed not to rely on its internal knowledge when generating results, since large language models are typically pre-trained on static sources like Wikipedia. By retrieving deity information directly from the vector store, the agent ensures that all subsequent computations—such as determining semantic closeness—are based on the same embedding space.
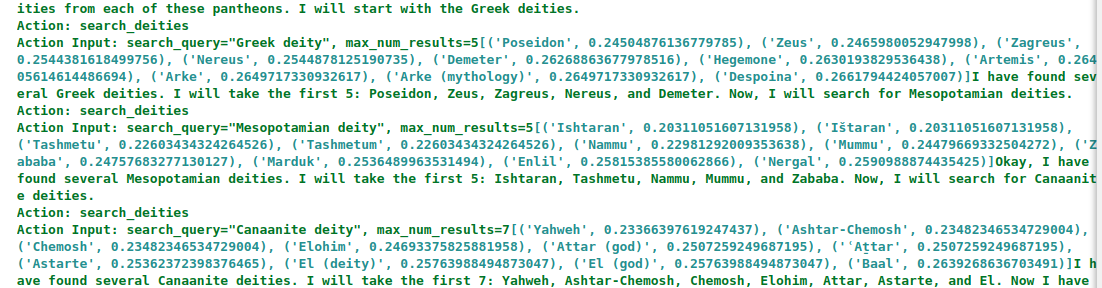
Once the agent has gathered the nodes for the response graph, it proceeds to generate the edges. To do this, it calls the create_deity_pairs tool.

Next, the agent attempts to identify and label relationships between the deity pairs, where applicable, by invoking the get_deity_relations tool.

At this stage, the agent is ready to compute the semantic closeness between the nodes of the graph. To do so, it invokes the calculate_relation_distances tool, which measures the similarity between deity embeddings retrieved from the vector store.

The agent constructs the complete deity graph by invoking the format_json_output function, which assembles the nodes, labeled edges, and computed distances into a structured JSON representation.
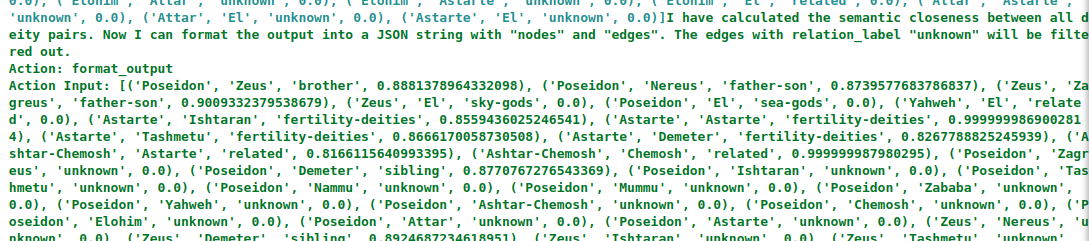 This process culminates in the final JSON response.
This process culminates in the final JSON response.

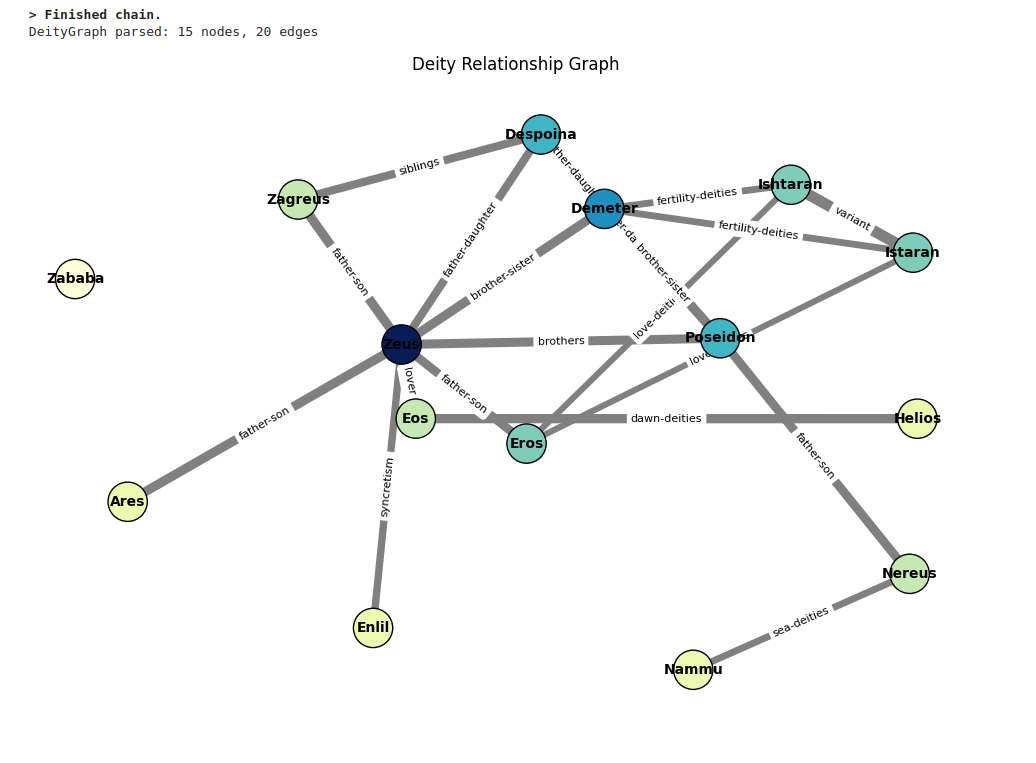
Finally, Promptheon converts the DeityGraph returned by the ReAct agent into a NetworkX graph and renders it as a visual representation of the discovered relationships.
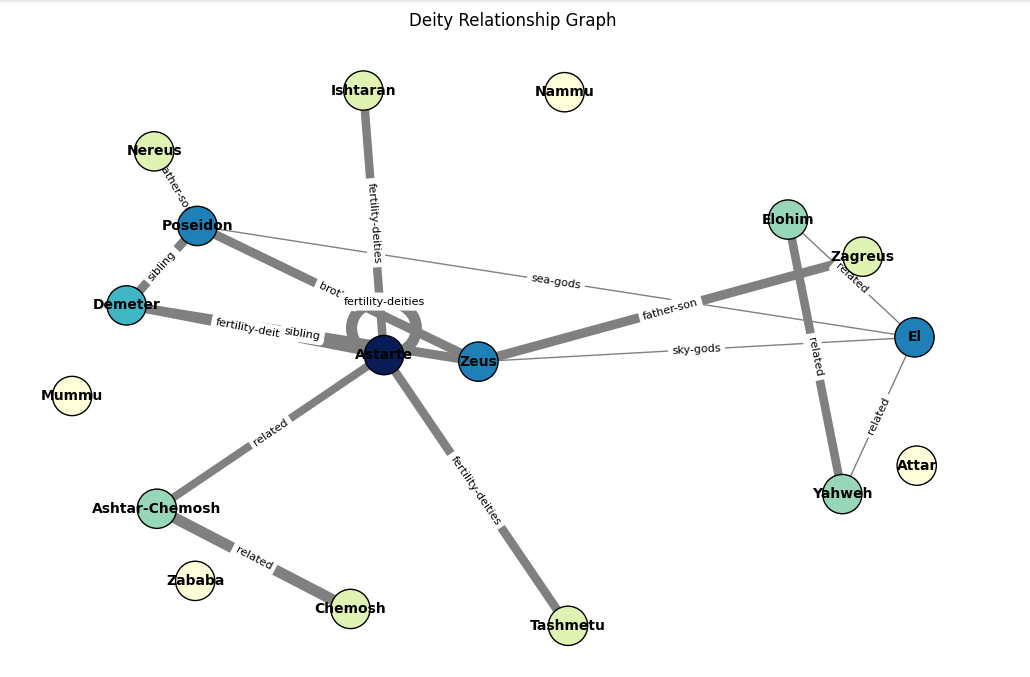
This graph illustrates symbolic relationships between deities from three pantheons: Greek, Mesopotamian, and Canaanite. Some figures, such as El and Zeus, are linked by role (both are sky gods), yet remain semantically distant—according to their respective Wikipedia embeddings. Notably, the graph forms a complete triangle (K₃) connecting El (Canaanite), Yahweh (Jewish), and Elohim (Jewish), with all edges loosely labeled as “related.” However, the semantic distances reveal meaningful nuance: while the edge between El and Elohim has a distance close to zero, the distance between El and Yahweh is significantly larger (0.8633), suggesting a weaker textual affinity between those pages. It turns out that the Wikipedia page for El referenced in this case points to a general portal page, rather than the specific article on the Canaanite deity El (deity). This misreference likely explains both the symbolic relation labels and the zero semantic distances observed between El, Elohim, and Yahweh.
Another interesting pattern emerges around the label “fertility-deities.” The connection between Astarte (Canaanite) and Demeter (Greek) is well-established, given their widely recognized roles as fertility goddesses. However, other cases are more speculative. Consider Astarte and Ishtaran (Mesopotamian): according to his Wikipedia page, Ishtaran is a male deity. Yet the same source suggests that Ishtaran might represent a dual form of Ishtar (aka Innana) (Mesopotamian), a major fertility goddess—derived from the dualizing suffix “-an” in some Semitic languages. If this interpretation holds, Ishtaran could symbolically represent "the two Ishtars"—and thus be indirectly associated with fertility.
Flagging Tashmetum (Mesopotamian)—"she who listens"—as a fertility deity, however, appears more tenuous, as the attribution is not clearly supported by textual evidence.
Despite occasional ambiguity, the graph surfaces compelling insights into thematic parallels and symbolic roles across these ancient pantheons.
What if not?
One might wonder: How does Promptheon handle prompts that include negative constraints? Let’s explore this by testing a more nuanced query. We ask Promptheon:
"Who were the most important gods in Athens who were not war gods or goddesses?"
Here’s how the agent responds.
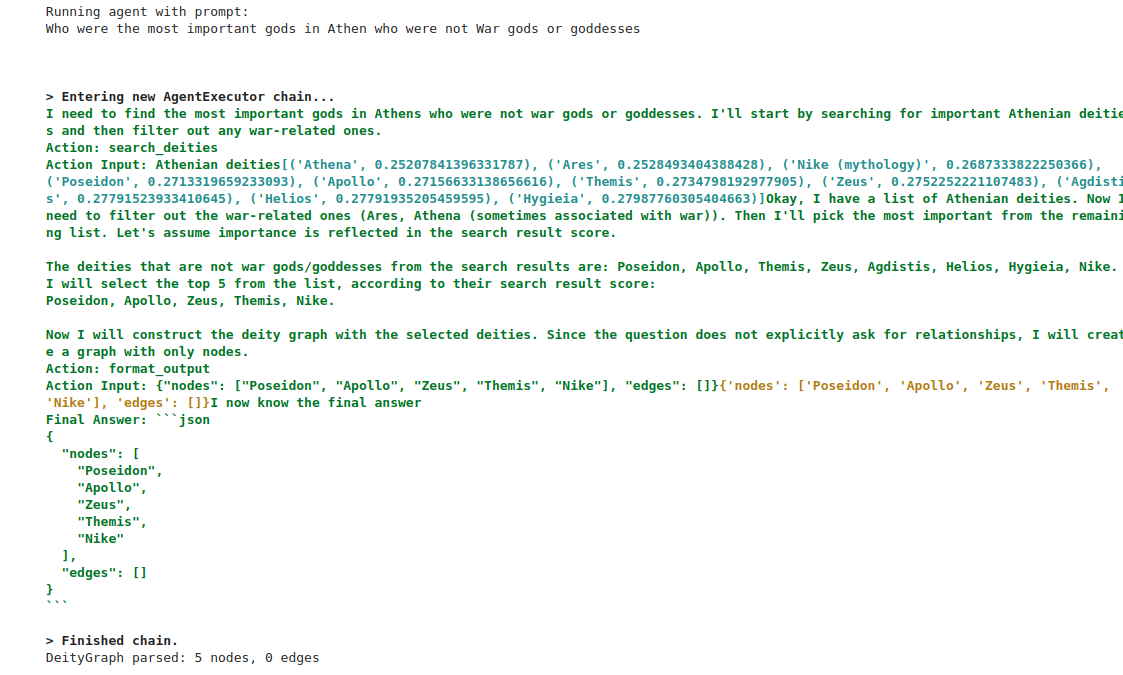
In response to the prompt, the agent first used the search_deities tool to retrieve a list of Greek deities. It then relied on its internal knowledge to filter out Ares and Athena, both known war deities. Interestingly, the agent stopped at this filtering step—it did not proceed to build relationships between the remaining deities, nor did it compute semantic distances among them.
To address this limitation, I refined the prompt to be more explicit:
"Who were the most important gods in Athens who were not war gods or goddesses, and provide the relations between the non-war deity pairs."
This clarified instruction successfully triggered the invocation of both the relationship-generation and labeling tools.
IV- Embedding and Persisting Deity Pages
An embedding is a vector representation of a word within a specific context. It maps the word into a high-dimensional space—typically ranging from a few hundred to several thousand dimensions—where semantic similarity corresponds to geometric proximity. Similarly, a document embedding is a single vector that represents the entire document. It is often computed as the average (or weighted average) of the embeddings of the words it contains.
Embeddings enable mathematical operations on textual data by representing documents as vectors in a continuous vector space. One application is measuring the similarity or distance between documents by comparing their corresponding embedding vectors. In this project, we leverage this capability to assess semantic closeness between deity pages. Specifically, we use cosine distance. The cosine distance between vectors $\overrightarrow{u}$ and $\overrightarrow{v}$ is defined as $$ \frac{\overrightarrow{u} \cdot \overrightarrow{v}}{\vert\vert \overrightarrow{u} \vert\vert * \vert\vert \overrightarrow{v} \vert\vert} $$.
Since averaging word embeddings across an entire deity page can dilute the semantic meaning—especially for longer texts—we split each page into smaller chunks to preserve contextual coherence. To achieve this, I used TokenTextSplitter, which segments the text based on token count. Each chunk is then individually embedded using Google's Gemini model, models/text-embedding-004. The code snippet below shows the custom embedding function used in Promptheon to perform this operation.
class GeminiEmbeddingFunction(EmbeddingFunction):
"""
Embeds documents using a Gemini's embedding, returning vectors for semantic search.
"""
def __init__(self, politeness_delay_ms: int):
self.politeness_delay_ms = politeness_delay_ms
def __call__(self, documents: Documents) -> Embeddings:
embeddings = []
for doc in documents:
embedding = client.models.embed_content(
model=EMBEDDING_MODEL,
contents=doc,
config=EmbedContentConfig(task_type='semantic_similarity')
).embeddings[0].values
embeddings.append(embedding)
# Throttle to respect embedding model,s api rate limits.
time.sleep(self.politeness_delay_ms / 1000)
return embeddingsA politeness delay is introduced in the constructor of GeminiEmbeddingFunction to comply with the rate limits imposed by the embedding model—specifically, a maximum of 150 requests per minute. In this project, a delay of 400 milliseconds was used to stay safely within that limit. This embedding function instance is passed to ChromaDB when creating a new collection for building the vector store, as well as when accessing an existing collection for query search and vector retrieval.
politeness_delay_ms = 400 # Throttling calls to the embessding model.
db_collection = chroma_client.get_or_create_collection(
name=DB_COLLECTION_NAME,
embedding_function=GeminiEmbeddingFunction(politeness_delay_ms ),
metadata=collection_metadata
)Special care must be taken when building a vector store in one environment (e.g., a local machine) and exporting it to another (e.g., a Kaggle runtime). ChromaDB provides a set of configuration variables that govern the structure and behavior of the embedding space. In this project, these configurations are managed through a wrapper class, shown below.
class EmbeddingSpaceConfig(pydantic.BaseModel):
"""
Configuration of the embedding space associated to a ChromaDB collection.
Attributes:
distance (str): Distance metric used for similarity search. Must be one of: 'l2', 'cosine', 'ip'.
indexing_neighborhood_size (int): The 'ef_construction' parameter (HNSW indexing depth). Must be > 0.
search_neighborhood_size (int): The 'ef' parameter used during search. Must be > 0.
max_neighbors_count (int): The 'M' parameter, controlling graph connectivity. Must be > 0.
"""
distance: Literal['l2', 'cosine', 'ip'] = 'cosine'
indexing_neighborhood_size: conint(gt=0) = 100
search_neighborhood_size: conint(gt=0) = 100
max_neighbors_count: conint(gt=0) = 16
def to_metadata(self) -> Dict[str, str]:
return {
'hnsw:space': self.distance,
'hnsw:construction_ef': self.indexing_neighborhood_size,
'hnsw:search_ef': self.search_neighborhood_size,
'hnsw:M': self.max_neighbors_count,
'hnsw:num_threads': 2
}
default_emb_space_config = EmbeddingSpaceConfig()The num_threads configuration in ChromaDB requires particular attention. It controls the level of parallelism used both during vector store construction and while performing search operations. By default, this value is set to the number of CPU cores available on the machine where the index is created. Crucially, this configuration is persisted with the vector store and cannot be modified afterward—at least in the version of ChromaDB used for this project.
This becomes problematic when transferring a store between environments with differing hardware capabilities. For instance, if you build the vector store on a machine with eight cores and later attempt to use it in a Kaggle runtime—where typically only four cores are available—ChromaDB will reject the collection. This is because hnsw:num_threads (in this case, set to 8) exceeds the number of available CPU cores in the new environment, and ChromaDB enforces this limit strictly.
This was one of the more painful lessons I learned during the project.
In this initial release, approximately 820 deity pages were processed and embedded, resulting in a vector store containing around 5,100 embeddings. Each embedding vector has a dimensionality of 768, and the total disk space consumed by ChromaDB is approximately 55 MB. The resulting vector store was uploaded to Kaggle as a dataset and integrated into the project’s notebook as an input resource.
V- Crawling Wikipedia
The crawler is built using the wikipedia Python package. It performs a two-hop traversal: starting from the List of Deities category page, which aggregates links to various deity portals, it first navigates to each portal and then visits the individual deity pages linked within them.
The Gemini LLM is leveraged at two key stages of the crawling process: first, to tag portal links found on the List of Deities category page, and second, to identify deity page links within each portal.
To take advantage of the categorization work done by Wikipedia contributors, I chose to tag the portal links listed on the List of Deities page. This also served as a valuable opportunity to experiment with prompt engineering.
Some portals group deities by culture (e.g., List of Celtic deities), others by role (e.g., List of war deities), and some by both. To extract this information reliably, a response schema was defined to guide the LLM in generating structured output.
# Response schema for tag prompts.
class TaggedDeityPortal(pydantic.BaseModel):
page_title: str
culture_tags: list[str]
role_tags: list[str]
def __str__(self):
parts = [f"page_title: {self.page_title}"]
if self.culture_tags:
parts.append(f"culture_tags: {self.culture_tags}")
if self.role_tags:
parts.append(f"role_tags: {self.role_tags}")
return "{" + ", ".join(parts) + "}"
class TagDeityPortalsResponse(pydantic.BaseModel):
tagged_portals: list[TaggedDeityPortal]I experimented with several prompts to accomplish the portal tagging task. All prompts are included in the notebook mentioned earlier and are properly versioned for reference. The final version is shown below.
# Tag a Wikipedia deity page prompt template
# template_id: tag_prompt_v4
# type: zero-shot
# format-output: Yes
# schema: TagDeityPortalsResponse
tag_prompt_v4 = """You are an expert in ancient religions and deities. You are given a list of DEITIES_LIST. Your job is to tag each DEITIES_LIST.
There are two types of tags and only two types: deity role tags and cultural tags:
* Deity role tags indicate the role of the deities in the DEITIES_LIST.
* Culture tags indicate the culture or region where the deities in a DEITIES_LIST were worshipped.
DEITY ROLES: A deity role may refer to the function of some deity. It can also be an element of nature to which the deity is associated
or any other abstract concept.
A DEITIES_LIST might have zero, one or many deity role tags. A DEITIES_LIST might have zero, one or many culture tags.
You must answer in JSON format. Tags must be normalized.
TAG NORMALIZATION:
Normalizing a tag means converting the tag string to uppercase and replacing any space character by an '_' character. Contiguous space characters
and contiguous underscores must be squeezed.
RESPONSE JSON SCHEMA:
TaggedDeityPortal = {page_title: string, culture_tags: list[string], role_tage: list[string]}
Response: {tagged_portals: [TaggedDeityPortal]}
list of DEITIES_LIST: {{list_of_deities_list}}
"""This is a zero-shot prompt—meaning it does not provide the LLM with examples to guide the tagging task. Notably, the prompt includes a clear definition of what constitutes a deity role (see DEITY ROLES), which proved essential for accurate tagging. For instance, without this section, the LLM consistently failed to tag portals like Sky deities correctly. The prompt also instructs the model to normalize the tags (see TAG NORMALIZATION). Overall, the tagging task was completed with relative ease, highlighting the strength of LLMs in automating tasks that would traditionally require substantial manual effort, such as maintaining a taxonomy of roles and cultures and resolving linguistic nuances.
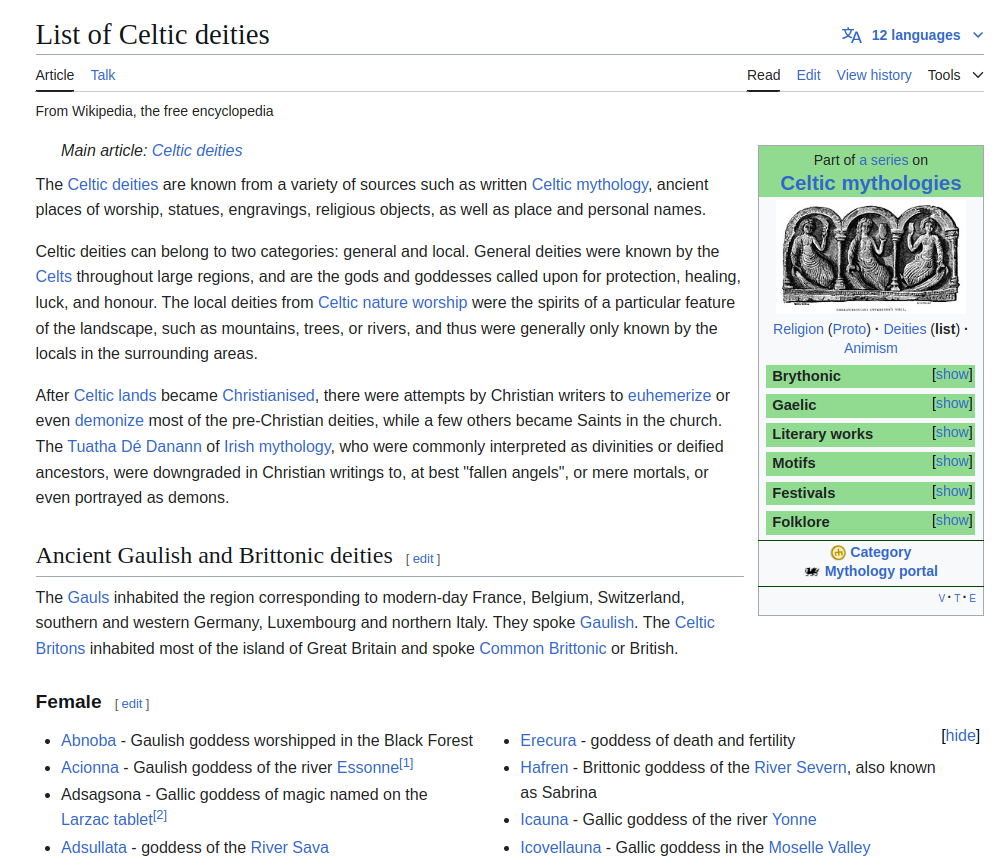
As shown in the figure above, a portal page contains links to deity pages but also to pages referencing places, cultures, and other non-deity entities. To ensure the crawler visits only relevant deity pages, an LLM-based filtering task was defined. The final prompt used for this task is shown below.
# Filter Wikipedia links that refer to a deity. Precise definitionn of what a deity link is.
# template_id: filter_deity_links_v2
# type: zero-shot
# format-output: Yes
# schema: FilterDeityLinksResponse
filter_deity_links_v2 = """You are an expert in ancient religions and deities. You are given a list of wikipedia link titles called LINKS_TITLES.
These links have been collected from a Wikipedia page titled {{parent_wiki_page}}. Your task is to split LINKS_TITLES into two classes: DEITY_LINKS and OTHER_LINKS.
* DEITY_LINKS: A list of all the items from LINKS_TITLES that refer to a deity and only these links.
* OTHER_LINKS: The items in LINKS_TITLES that do not refer to a deity.
Deity link: a link that refers to a single deities only. Links referring to lists of deities are not considered deity links.
You must answer in JSON format.
RESPONSE JSON SCHEMA:
FilterDeityLinksRespSchema = {"deity_links": list[string], "other_links": list[string]}
LINKS_TITLES: {{links_titles}}
"""It’s important to note that this prompt clearly defines what qualifies as a deity link. Omitting this definition initially led the LLM to incorrectly identify links to other List of deities pages as deity links. Since the goal was to implement a two-hop crawler, it was essential to instruct the LLM to restrict its selection to individual deity pages only.
To sum up this section, prompt engineering is much like debugging software—an iterative process that requires refining prompts to make them more specific and aligned with the prompt engineer’s intent. The goal is to eliminate any discrepancies between the human’s expectations and the LLM’s interpretation.
VI- Conclusions and Future Work
In this article, I presented the architecture of Promptheon and detailed the implementation of its core components. I also shared key lessons learned while designing ReAct agents, building vector stores, and refining LLM prompts.
There are several directions in which this work can be extended:
Expand the vector store by crawling all portals listed under the List of Deities category. This would improve deity coverage and enable richer, more complex queries.
Enhance the deity relationship prompt by refining instructions for relation discovery and labeling. Although the current prompt asks the LLM to avoid trivial relationships, the model occasionally returns generic results like "deity–deity."
Adopt SigmaJS instead of NetworkX for visualization. SigmaJS supports interactive graphs and event bindings, which would allow features like displaying deity summaries on node click or revealing relationship labels on edge hover.
Deploy Promptheon as a web application accessible via promptheon.ca, making it publicly available for exploration.