Google’s generous free-tier limits once made Gemini an ideal platform for experimenting with LLM-powered applications. When those limits quietly changed, a YouTube recommendation system that had worked reliably for months suddenly stopped functioning. This post recounts that experience and explores what it reveals about the hidden risks of building on third-party AI platforms.
Google’s Developer Attraction Strategy — The Golden Era
Over the past couple of years, Google did an impressive job attracting developers to its AI ecosystem. Through collaborations with platforms like Kaggle, Google offered free courses on generative AI and AI agents, effectively lowering the barrier to entry while simultaneously promoting its own AI models and libraries. These initiatives helped position Google as an accessible and developer-friendly player in the rapidly evolving LLM space.
What truly set Google apart at the time, however, was the generosity of its free-tier rate limits. For content generation models, there was no cap on the number of requests per minute (RPM), while embedding models came with a fair limit of 100 RPM. Developers also benefited from a daily allowance of one million tokens per day (TPD). It was unclear whether there was any explicit limit on the number of requests per day (RPD), which further reinforced the perception of a highly permissive free tier.
This combination of education, tooling, and generous usage quotas encouraged a wide range of users—developers, hobbyists, researchers, and startups alike—to experiment with Google’s models. As a result, many LLM-powered applications emerged, spanning use cases such as automation and home automation in particular. For anyone looking to prototype or build AI-driven applications without immediately committing to a paid plan, Google’s ecosystem was, at that time, especially attractive.
A Developer’s Journey — Building with Gemini
Encouraged by Google’s accessible AI ecosystem and generous free-tier limits, I developed several applications using Gemini models and planned to build more. The low friction around experimentation made it easy to explore practical, LLM-powered ideas without having to immediately think about cost optimization or aggressive request batching.
One of these applications was a YouTube video recommendation system designed as a customizable alternative to YouTube’s built-in recommendation algorithm. The application periodically pulled a large set of recently liked videos—on the order of the latest 1,000 items—from a user’s account. It then called a Gemini model to classify these videos into topics based on their titles . These topics were used to perform stratified sampling, with each topic treated as a separate stratum to ensure balanced representation across different interests.
The sampled video data, consisting of titles and descriptions, was then sent to the Gemini model to generate YouTube search queries aimed at retrieving videos similar to the original inputs. A subset of the resulting search results was automatically added to a dedicated YouTube playlist, which I called “LLM recommendations.” This playlist represented the output of the system and served as its personalized recommendation feed.
Deployed as a daily periodic job, the application worked reliably and produced high-quality recommendations for several months. From a developer’s perspective, this experience highlighted the value proposition of working with Gemini at the time: rapid prototyping, minimal operational overhead, and the ability to build useful, end-to-end applications powered entirely by LLMs.
The Rude Awakening — When Rate Limits Strike Back
After several months of smooth operation, I noticed in December that the “LLM recommendations” playlist had stopped being populated. Upon inspecting the application logs, it became clear that every single call to the Gemini API was failing with a 429 status code. The error message indicated that resources had been exhausted, suggesting that rate limits were being hit immediately, starting from the very first request.
At first, this behavior was puzzling. The API key used by the application was intentionally not linked to any billing account, but hitting rate limits on the first call was unexpected. The recommender relied on the gemini-flash-2.0 model, which had previously worked without issues. This led me to suspect either a problem with the API key itself or a silent change in how the model was being handled on the free tier.
More recently, I received an email from Google announcing that gemini-2.0-flash would be decommissioned by March 31st. This reinforced the suspicion that the model had effectively become unusable for free-tier users. I switched the application to use gemini-flash-2.5, and the first few API calls did go through—albeit very slowly. I was able to get some recommendations added to the “LLM recommendations” playlist, but I quickly started hitting rate limits again.
To better understand what was happening, I logged into AI Studio and examined the current rate limits. This is where the scale of the change became clear. Rate limits were now significantly more aggressive, with requests per minute (RPM) ranging from as low as 5 to 15 depending on the model. While the token limit remained at one million tokens per day (TPD), a new and much stricter constraint had been introduced: requests per day (RPD), capped at just 20.
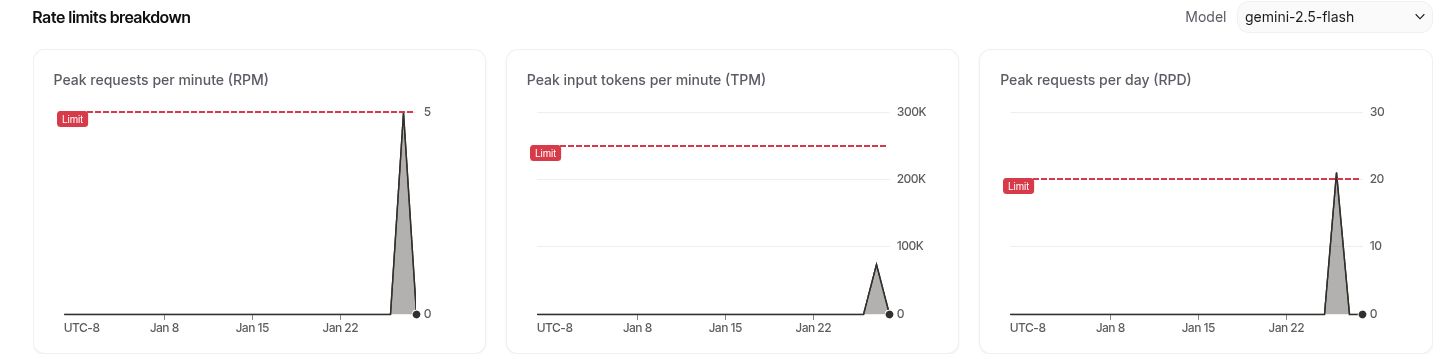
Google had made an announcement earlier about changes to these limits, describing three independent rate-limiting buckets—RPM, RPD, and TPD—where hitting any one of them would immediately result in 429 errors. The announcement mentioned an RPD of 250, yet many users reported being limited to only 20 RPD in practice. Several reports suggested that this discrepancy might affect users in certain western countries more than others, and that the intent was to push free-tier users toward Tier 1, the first paid tier.
While RPM constraints can be mitigated by adding politeness delays between successive API calls, the new RPD limit poses a far more fundamental challenge. Working around it requires bundling multiple logical requests into a single API call, which in turn forces changes to prompt design and application logic. At that point, rate limits stop being a minor operational detail and start dictating core architectural decisions.
The Broader Impact — Why This Matters for the AI Ecosystem
These changes highlight a deeper issue with building applications on top of tightly constrained APIs. Rate limits such as RPM, RPD, and TPD do not merely affect throughput; they actively shape how applications are designed. When those limits become overly restrictive, developers are forced to either significantly refactor their code to accommodate new constraints or reconsider their choice of vendor altogether.
More concerning is the lack of predictability. In this case, it appears that Google effectively set some limits to zero for certain models and tiers—such as gemini-flash-2.0 for free-tier users—without providing clear, advance warnings. Applications that had been working reliably for months can stop functioning overnight, leaving developers unaware and unprepared for the change. This kind of silent breakage erodes trust, especially for those experimenting or building early-stage products.
In response, I decided to migrate to a different provider. X-AI currently offers more generous rate limits for several open-source LLMs, making it a viable alternative—at least until its own limits become similarly restrictive in the future. This experience underscores a broader reality of LLM-powered applications: unless you are hosting your own models, your application and, by extension, your business are vulnerable to vendor-side decisions. While this may be acceptable to some extent for personal projects, it becomes a serious concern as soon as reliability and longevity matter.
Migration to Groq
Switching from the Gemini to the Groq ecosystem was straightforward, requiring only the use of the Python module groq. When choosing a model, the following criteria came into play:
- The rate limits of the model. Some models offered more restrictive rates (very important).
- The model had to support multiple languages (important).
- The model has to support structured output (like gemini models). This basically saves me manually parsing the responses of the model. Not a blocker, but a nice to have.
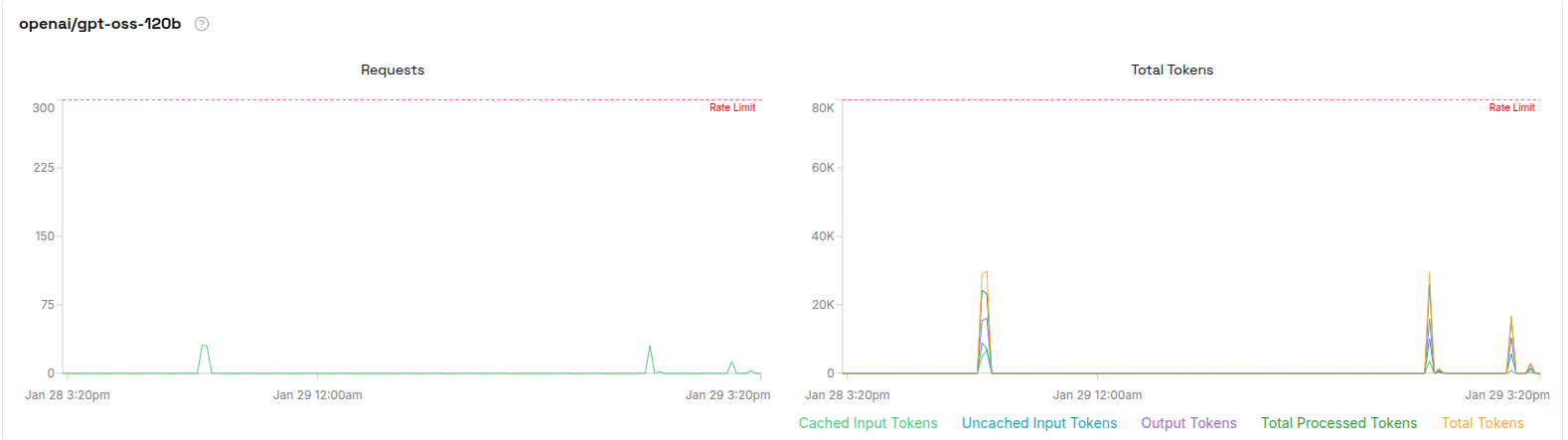
I ultimately settled on OpenAI’s gpt-oss-120B model. In fact, it—and its smaller counterpart, gpt-oss-20B—were the only OpenAI models that consistently produced structured responses with strict adherence to the JSON schema provided to the LLM. The figure below shows some usage stats.