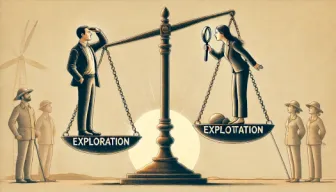
In this article, we’ll walk through the implementation of a one-dimensional, binary-state cellular automaton built on top of the parametric CA framework I introduced in a previous post. The single-page app is split into two pieces: the cellular-automaton engine itself, and a graphical user interface (GUI). The GUI includes two PixiJS renderers—one for the rule and one for the grid.